OpenAI「复活」了 QQ宠物,网友直接玩疯,把奥特曼和他死对头都养在了电脑里
OpenAI「复活」了 QQ宠物,网友直接玩疯,把奥特曼和他死对头都养在了电脑里谁不想在自己的电脑上养一只小宠物,打开电脑,它就坐在那里看着你工作。 OpenAI 最近在 Codex 上的更新,引入了类似电子宠物 Tamagotchi 的桌面悬浮伴侣。 我们可以在摸鱼的时候,把鼠
来自主题: AI资讯
8653 点击 2026-05-03 22:49
 搜索
搜索
谁不想在自己的电脑上养一只小宠物,打开电脑,它就坐在那里看着你工作。 OpenAI 最近在 Codex 上的更新,引入了类似电子宠物 Tamagotchi 的桌面悬浮伴侣。 我们可以在摸鱼的时候,把鼠

近日,美国五角大楼宣布与七家公司达成协议,包括 OpenAI、谷歌、微软、亚马逊、英伟达、SpaceX 和一家名为 Reflection AI 的初创公司,允许将这些公司的 AI 系统用于机密级别的军

OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。

今天,OpenAI 官方播客发布了一期节目,让内部研究员 Sebastian Bubeck 和 Ernest Ryu 出来回答这一问题,毕竟大家都十分好奇。Ernest 近期刚加入 OpenAI 担任研究员,他之前是加州大学洛杉矶分校(UCLA)数学系的教授,研究优化和机器学习理论。他是最早尝试用 ChatGPT 解数学开放问题的那批人之一。
一个开发者公开了自己的工作流:让 OpenAI Codex 专门去审查 Hermes agent 写出来的代码,理由只有一个——审稿人不能和写稿人共享同一套记忆。这条推文引发了近万次浏览,背后藏着一个 agent 工程化的新趋势:多模型协作的价值,可能在于互相制衡。
想象一下:你打开浏览器,没有代码、没有 HTML、没有 CSS 布局引擎。屏幕上每一帧画面,都是 AI 模型实时生成的像素视频流。满满的科幻降临既视感!这就是 Zain Shah(前 OpenAI、YC 校友)和团队刚刚发布的 Flipbook 原型。
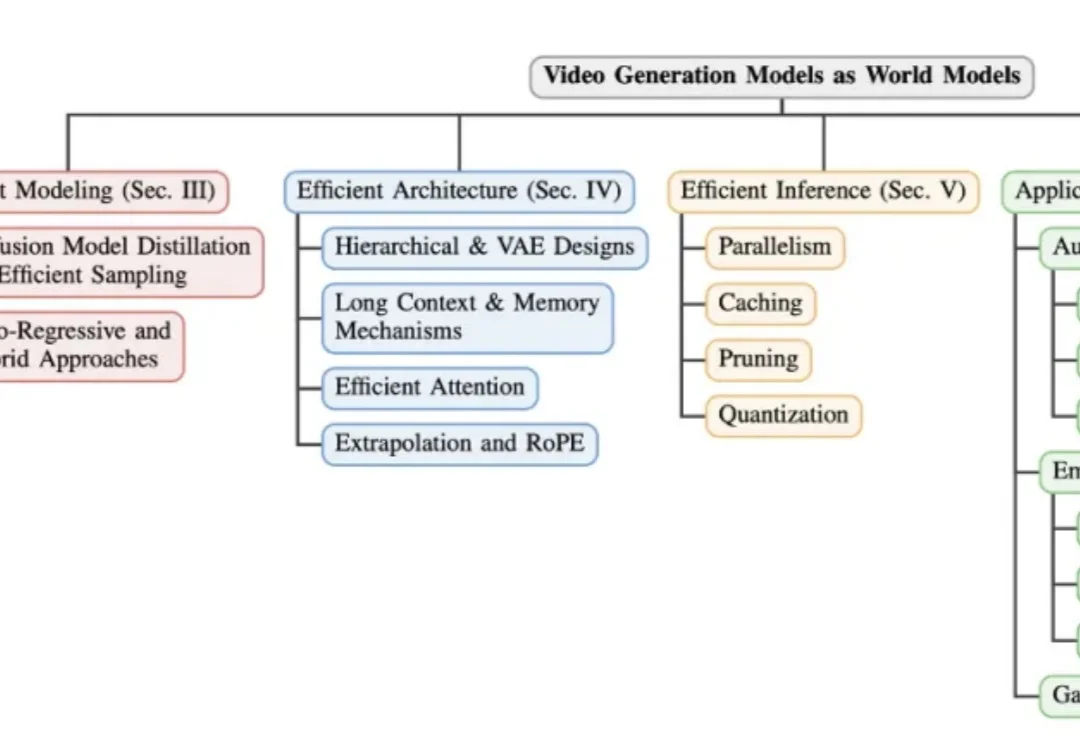
还记得两年前,AI 生视频可谓是「鬼畜专区」—— 人物多一根手指算基操,走路自带鬼步舞才是常态。结果转眼间,从 OpenAI 的 Sora 到字节跳动的 Seedance,这些模型已经开始一本正经地「模拟世界」了:水会流、球会弹、光影能追踪,俨然一副要当「物理引擎」的架势。

Anthropic 在私募二级市场被追到接近 1 万亿美元,热度反超 OpenAI,背后是稀缺股权、收入增长、Claude Code 的产品势能,以及资本对 AI 平台入口的重新下注。
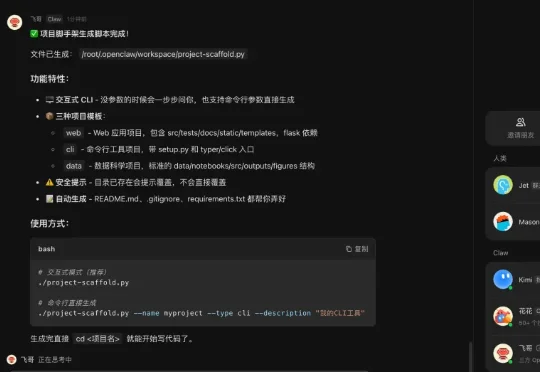
这两周国内外的 AI 圈又开始密集更新了。 上周 Anthropic 发了 Opus 4.7,这周 OpenAI 上了 GPT Image 2。国内这边 Kimi 发了 K2.6,腾讯据说也要发一个模

当一家成立不到两年、团队规模不过 10 人的创业公司被收购,并在数周内关闭产品、清空数据,这通常不会成为行业关注的焦点。但这一次不同。收购方是 OpenAI,而被收购的,是一家试图用模型重写个人理财方式的初创公司——Hiro Finance。